背景
最近看到一个分享:提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告,微信年度聊天报告觉得挺有意思的,可惜作者搞的是 Windows 的版本,像我这种 Mac 用户就无法使用了。
既然没有办法解析 Mac 微信的数据文件,那么我就想是不是可以通过其他方式实现呢?
思考
直接从微信拿数据短期应该行不通,只能从其他地方找一些行为数据,巧的是为了隐私安全我今年把输入法切换成了雾凇拼音,它不但不会联网,而且它的词库也全部都存储在本地,并且可以多设备同步。


那么既然词库都在本地,而且是明文的,确实是很好的做成年度词云的素材数据库。
先看下本地个人词库的数据格式
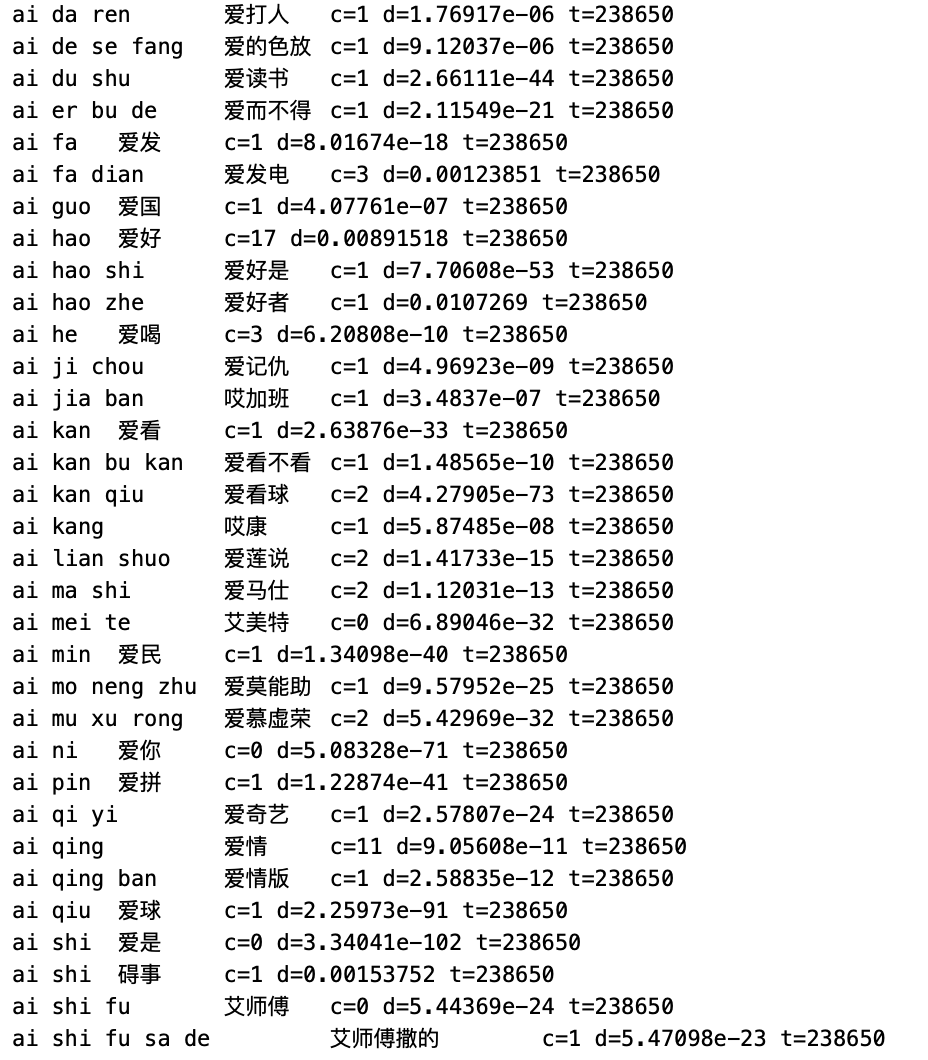
操作
解析 json
格式还是比较标准的,先把本地词库 rime_ice.userdb.txt 处理成方便使用的 json 格式,简单的文件操作还是使用 Node.js 来实现。
let ciyunArr = data.split("\n");
console.log(data.split("\n"));
const extractedValues = ciyunArr.map(item => {
const splitValues = item.split('\t');
const words = splitValues[1];
const cValue = item.match(/c=(\d+)/); // c=后面的数字是词频
const count = cValue ? parseInt(cValue[1]) : null;
return { words, count };
});
然后稍作排序,去掉词频小于 120 次和小于两个字的
const filteredData = extractedValues.filter(item => {
return item.count > 120 && item.words.length > 1
});
let templateArr = filteredData;
const jsonData = JSON.stringify(templateArr, null, 2);
fs.writeFile('data1.json', jsonData, 'utf8', err => {
if (err) {
console.error('Error writing file:', err);
return;
}
console.log('File has been saved!');
});
这时我们就得到了 json 格式的本地词频数据了。

数据已经解析出来了,下面就是如何让数据变成变成词云页面。
变成词云页面
之前给新员工做通用培训时刚好用 CSS 搞了个简单的词云页面,那就顺手拿来改一下。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>输入法词云 2023</title>
</head>
<body>
<script>
async function getData(params) {
let response = await fetch('/data1.json')
.then(response => response.json())
return response
}
var data = getData();
</script>
<ul class="cloud" data-show-value></ul>
<style type="text/css">
.cloud{
list-style: none;
padding-left: 0;
display: flex;
flex-wrap: wrap;
align-items: center;
justify-content: center;
line-height: 2.5rem;
}
ul.cloud a {
color: #a33;
display: block;
font-size: 1.5rem;
padding: 0.025rem 0.35rem;
text-decoration: none;
position: relative;
}
ul.cloud li:nth-child(2n+1) a { color: #118; }
ul.cloud li:nth-child(3n+1) a { color: #33a; }
ul.cloud li:nth-child(4n+1) a { color: #c38; }
ul.cloud li:nth-child(5n+1) a { color: rgb(51, 204, 94); }
ul.cloud li:nth-child(6n+1) a { color: rgb(51, 166, 204); }
ul.cloud li:nth-child(7n+1) a { color: rgb(173, 204, 51); }
ul.cloud[data-show-value] a::after {
content: " (" attr(data-weight) ")";
font-size: 1rem;
}
</style>
<script>
function adjustFontSize(size) {
const thresholds = [
{ max: 400, divideBy: 100 },
{ min: 400, max: 600, divideBy: 120 },
{ min: 600, max: 800, divideBy: 140 },
{ min: 800, max: 1000, divideBy: 150 },
{ min: 1000, max: 2000, divideBy: 250 },
{ min: 2000, max: 4000, divideBy: 300 },
{ min: 4000, max: 10000, divideBy: 400 }
];
const threshold = thresholds.find(thresh => {
if (thresh.max && thresh.min) {
return size > thresh.min && size <= thresh.max;
} else if (thresh.min) {
return size > thresh.min;
} else if (thresh.max) {
return size <= thresh.max;
}
});
if (threshold) {
console.log(threshold.divideBy, size);
return size / threshold.divideBy;
}
}
data.then(function (res) {
const htmlElements = res.map(item => `<li><a href="#" data-weight="${item.count}" style="font-size:${adjustFontSize(item.count)}rem">${item.words}</a></li>`);
const htmlString = htmlElements.join('\n');
document.querySelector('ul.cloud').innerHTML = htmlString;
})
</script>
</body>
</html>
最终效果
数据做了简单的脱敏,效果是不是像那么回事,虽然无法精确到某个软件的数据反而你先,但是只要打字就会用输入法,所以输入法的数据会更佳的宏观,最终结果也比较符合我的语气。
多字版

单字版
